
AWS Outage: Why Infrastructure Diversity Matters

The October 2025 AWS Outage Should Be Your Wake-Up Call: Why Infrastructure Diversity Matters
Early Monday morning, October 20th, the digital world held its breath. Amazon Web Services experienced a massive outage starting around 3:11 AM ET that brought down thousands of websites and applications for over six hours. Snapchat, Roblox, Fortnite, Robinhood, and countless other platforms went dark. Airlines scrambled as their booking systems failed. Banks locked customers out of their accounts. Smart home devices stopped responding.
The culprit? A DNS resolution failure and networking issues in AWS’s US-East-1 region in Northern Virginia. For those keeping score, this region is one of the busiest data center hubs in the world. When it goes down, much of the internet follows.
But here’s what bothers me most about this incident: it was entirely predictable. Not the specific timing or technical cause, but the fact that putting all your eggs in one basket would eventually cause problems. And yet, thousands of businesses continue to do exactly that.
The True Cost of Cloud Concentration
According to Mehdi Daoudi, CEO of internet performance monitoring firm Catchpoint, the financial impact of this outage will easily reach into the hundreds of billions of dollars. That number accounts for lost productivity, halted business operations, delayed shipments, and customers who couldn’t access services they paid for.
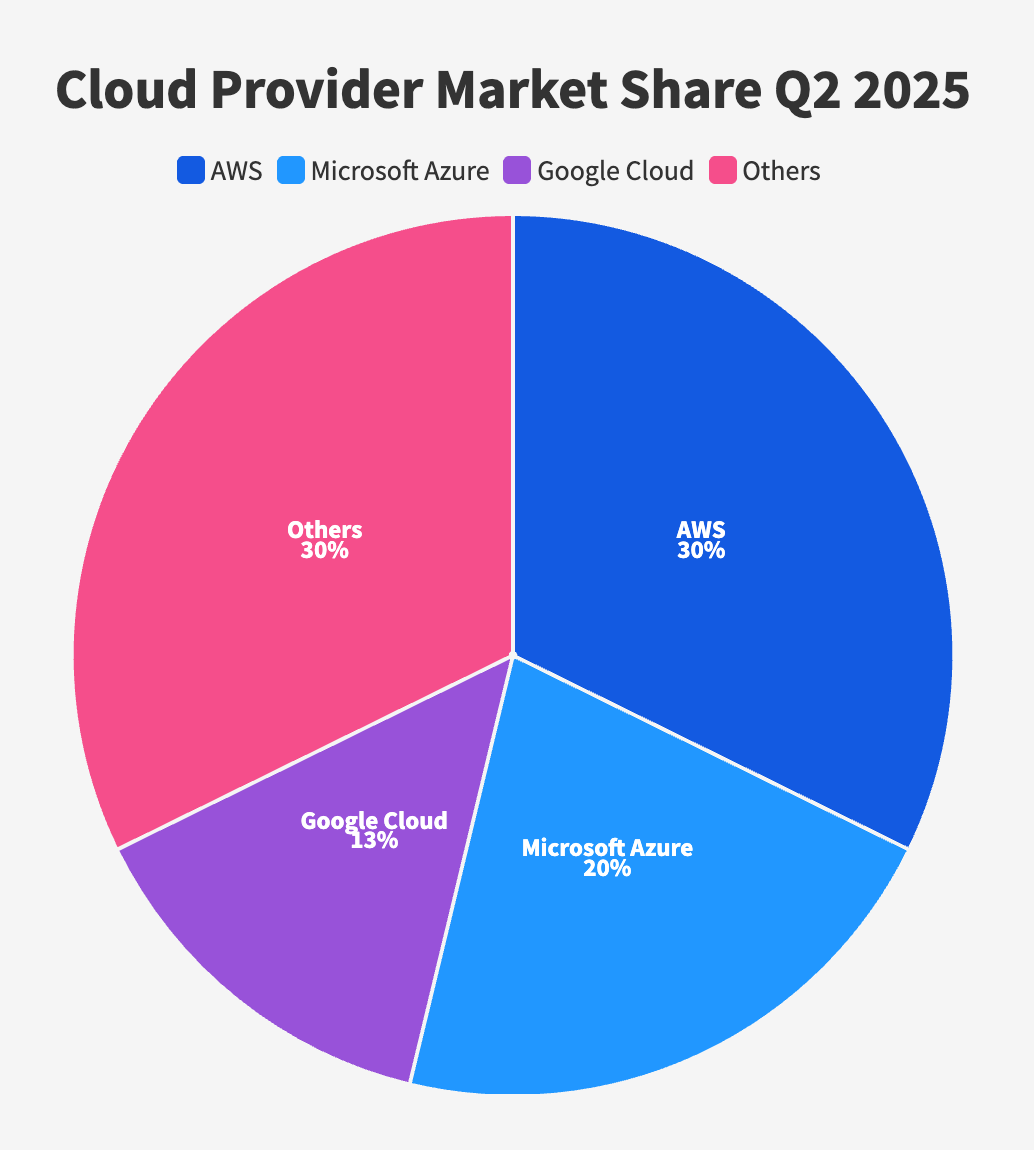
Think about that for a moment. Hundreds of billions in losses because one company’s infrastructure had a bad morning. This isn’t a knock on AWS specifically. Their infrastructure is generally robust and reliable. But when 30% of the cloud computing market runs on a single platform, a single point of failure becomes a global catastrophe.
The Reality Check: Research from Gartner has identified cloud concentration as one of the top 5 emerging risks for organizations. When your business depends entirely on one cloud provider, you’re not just trusting their infrastructure. You’re betting your entire operation on it.
What Businesses Get Wrong About Cloud Reliability
Many companies assume that deploying applications across multiple availability zones within AWS provides sufficient redundancy. They believe distributed computing within a single cloud environment protects them from outages.
Monday’s incident proved otherwise. The outage didn’t just affect one availability zone. It cascaded across the entire US-East-1 region, taking down EC2 instances, S3 storage, and DynamoDB databases simultaneously. All those carefully architected multi-zone deployments? They went down together because they all relied on the same underlying infrastructure.
A Better Approach: True Infrastructure Diversity
The solution isn’t to abandon cloud services entirely. Cloud computing offers undeniable benefits in terms of scalability, flexibility, and operational efficiency. The solution is to stop treating any single cloud provider as your only lifeline.
Co-Location with Dedicated Servers
This is where co-location strategies with dedicated servers become critical. By distributing your infrastructure across multiple providers and multiple data centers, you eliminate single points of failure. When one provider experiences issues, your traffic automatically routes to healthy infrastructure.
A proper dedicated server hosting strategy means you’re not just diversifying providers. You’re diversifying the entire technology stack:
- Different cloud providers (AWS, Azure, Google Cloud)
- Different geographic regions and data centers
- Different Internet Service Providers
- Different hardware vendors and platforms
- Mix of cloud and dedicated infrastructure
The Hybrid Infrastructure Model
The most resilient approach combines cloud flexibility with dedicated hardware reliability. Keep your dynamic, scalable workloads in the cloud where they can grow and shrink based on demand. But keep your critical, predictable workloads on dedicated servers in co-location facilities.
This hybrid model provides several advantages:
Cost Predictability: Dedicated servers offer flat monthly costs without surprise egress fees or bandwidth overages. You know exactly what you’re paying every month.
Performance Consistency: When you’re not sharing resources with thousands of other tenants, performance stays stable. No noisy neighbor problems. No sudden throttling during peak times.
Control and Visibility: You have complete visibility into your infrastructure. You can see exactly what hardware you’re running on, how it’s configured, and what security measures protect it. Cloud services remain largely a black box.
Dedicated Infrastructure + Cloud Flexibility = Business Resilience
Learning From Financial Services
The financial sector learned this lesson years ago. JPMorgan Chase, for example, deliberately maintains a multi-cloud strategy. They spread critical workloads across multiple providers specifically to avoid the concentration risk that bit so many companies on Monday.
If you’re thinking “but I’m not JPMorgan,” consider this: your customers don’t care about your size when your services go down. They just know they can’t access what they paid for. The startup that loses its entire revenue stream during a six-hour outage faces just as much existential risk as the enterprise that loses millions.
The Vendor Lock-In Problem
One reason companies hesitate to diversify is vendor lock-in. Cloud providers make it easy to migrate in but expensive and complex to migrate out. High egress fees, proprietary services, and incompatible technologies create barriers that keep you trapped.
This is intentional. When migration costs are prohibitive, you’re stuck even if service quality degrades or prices increase. The Monday outage is a perfect example. Companies knew they had a single point of failure. But the perceived cost and complexity of changing kept them locked in until disaster struck.
Working with a managed hosting provider that maintains vendor neutrality solves this problem. They can orchestrate infrastructure across multiple providers while keeping everything integrated and manageable from your perspective.
What You Should Do Right Now
If Monday’s outage affected your business, don’t wait for the next one to take action. Here’s what a realistic mitigation strategy looks like:
Audit Your Dependencies: Map out exactly which services and infrastructure you rely on. Identify your single points of failure. Be honest about what would happen if each provider went down for six hours.
Prioritize Your Workloads: Not everything needs to be distributed across multiple providers immediately. Start with your most critical services. What absolutely cannot go down without severe consequences?
Design for Portability: Use containerization and infrastructure-as-code to make your applications portable across providers. Avoid proprietary services that lock you into a single vendor’s ecosystem.
Test Your Failover: Having backup infrastructure doesn’t help if you can’t actually switch to it when needed. Regularly test your failover procedures. Make sure your team knows how to redirect traffic when primary systems fail.
Partner with Specialists: Managing multi-provider infrastructure is complex. Working with a managed hosting provider that specializes in hybrid cloud and co-location strategies can save you from expensive mistakes and operational headaches.
The Bottom Line: Diversifying your infrastructure isn’t just about avoiding downtime. It’s about maintaining control over your business destiny. When you’re not completely dependent on any single provider, you have negotiating power. You have options. You have resilience.
Moving Forward
The October 20th AWS outage will be studied in computer science courses for years to come. It will appear in case studies about infrastructure resilience and business continuity planning. Analysts will write reports. Regulators may even craft new requirements around cloud concentration risk.
But none of that helps your business if you’re still running everything on a single cloud provider when the next major outage hits. And there will be a next time. Complex systems fail. That’s not pessimism. That’s reality.
The question isn’t whether your provider will experience an outage. The question is whether your business can survive when it does. Companies that diversify their infrastructure across multiple providers, combine cloud flexibility with dedicated server stability, and design for portability will weather the next storm. Those that keep all their eggs in one basket will be scrambling to explain to customers why everything went dark.
Which category will your business fall into?
Ready to diversify your infrastructure? Explore InMotion Hosting’s dedicated server solutions and learn how our co-location hosting services can help you build a more resilient infrastructure. Our team specializes in hybrid hosting strategies that combine cloud flexibility with dedicated server reliability.







